
Stop Playing MITRE ATT&CK Bingo
How security leaders get ATT&CK wrong and what you can do about it


A common misconception of the MITRE ATT&CK framework is that it’s a cybersecurity version of Bingo. A game where you score points by covering columns and win by covering the whole board. This approach causes frustration for analysts who find themselves working on noisy alerts triggered by pointless rules. It also leads to wasted budgets and, worst of all, a false sense of security. But is there any other way to measure detection progress? And does ATT&CK still offer value to detection engineers and SOC leaders?
Mapping Tactics and Techniques
By now, most SOC practitioners are familiar with the table shown below. Each column represents a “Tactic” within the MITRE ATT&CK framework. These roughly correspond to Cyber Kill Chain stages, each being the threat actor’s steps towards their objective. The chain metaphor is helpful for defenders in the SOC, whose job is to break the chain and disrupt the attack before it can impact the business.

Naturally, security leadership wants to ensure that detections are deployed to spot attacks as early as possible. Each square in the matrix represents a technique attackers use at that stage. For example, an attacker may compromise a VPN service through stolen credentials or exploit a software vulnerability in the service itself.
The SOC leader may ask to review a heatmap like the above to confirm that detection coverage is in place. They may hear back from their team: “Good news, we’re covered for T1078: Valid Accounts.” In doing so, however, they risk turning a valuable tool into a high-risk Bingo game.
Mounting Concerns on ATT&CK Misuse
Leading infosec voice Mick Douglas recently suggested calling out cybersecurity products that advertise “100% MITRE ATT&CK coverage”:

This is the latest in a growing chorus of concerns about how security teams use the framework. Douglas pointed to alert fatigue as a major issue, while others like Forrester’s Josh Zelonis have pointed out the potential false sense of security. Zelonis described how “techniques such as Process Injection (T1055) have multiple methods of performing them that you would have to exhaustively research and test against.” In other words, your coverage heatmap might show that you covered a technique, but you would still miss an attacker executing the technique in a different way or on a system different from the “covering” detection expected.
The experts are right to raise the alarm. Marketing departments at leading cybersecurity vendors continue to create the impression that the ATT&CK framework is something you should try to cover. Google for “mitre attack coverage” and you’ll get ads like this one:

To avoid falling into this trap, switch from using ATT&CK as a goalpost to using it as a foundation for your detection engineering lifecycle.
ATT&CK for Threat Modeling
Instead of playing ATT&CK matrix bingo, use ATT&CK as a knowledgebase and common language for developing and prioritizing detection requirements. Keep in mind that ATT&CK was intended to represent the ways in which the bad guys operate. As such, it can help in every step along the Detection Responsibility Handshake.

First, ATT&CK gives us a way to talk about the threats facing the organization. If we’re worried about becoming the next UnitedHealth Group ($22 million in ransom, government investigation incoming), we might refer to the CISA advisory for the threat actor behind the breach. Five techniques associated with ALPHV Blackcat are laid out in the report:

These are critical components of the initial threat analysis performed in threat modeling.
Across these techniques, we refer to MITRE ATT&CK for associated data sources and components. Our objective at this stage is to understand the relevant systems and datasets. For example, knowing that the Blackcat group uses Kerberos token generation for domain access, we refer to technique ID T1558 and read up on the platforms affected by this technique: Linux, Windows, and macOS. We then apply knowledge of our environment and its vulnerabilities: maybe we’re a Windows shop, and some of our servers run an older version of the OS, which makes it easy to steal Kerberos tickets.
Looking up the threat actor’s technique on MITRE.org also yields guidance on what logs we need to collect. Notice that in the descriptions below, the idea of “coverage” gets very fuzzy. We can log “Service Ticket Operations” to the SIEM but only incrementally build detections to spot “irregular patterns of activity.” This one aspect of detecting the technique can take numerous detection engineering efforts.

Reviewing the rich details provided by MITRE, CISA, and independent researchers can show us what threat actors like Blackcat would likely try in our environment. Weighing the risk factors for our environment, we can design the detection requirements for the SOC to address. The team can then demonstrate coverage for its prioritized threat scenarios rather than the techniques of the ATT&CK framework.
ATT&CK for Building Detections
Knowing that ATT&CK coverage is not a goal to pursue doesn’t mean your detection engineering velocity doesn’t matter. On the contrary, the numerous ways attackers can operate in your environment should translate to greater urgency. As the SOC implements detections for the prioritized threat scenarios, the ATT&CK framework provides several opportunities to speed up detection engineering.
The first way to knock out detections faster is to get them from a detection content provider. Attackers reuse techniques across their victims and common targets, from Windows to AWS and Okta. Understanding your threat detection requirements regarding the MITRE technique links you to the relevant content in threat detection libraries like Anvilogic’s Armory. The fastest rule to build is one that someone else has already built.

Using ATT&CK as part of detection engineering is also important for efficiency at scale. As your team reuses detection components across tens or hundreds of multi-stage scenario detections in production, they need a systematic way to keep up with new components being created. For example, a detection scenario might look for a malware alert followed by indications of Windows autostart manipulation. This is a great way to spot an attacker that evaded endpoint protection. As your team adds additional rules for spotting this persistence technique, ATT&CK can link the new components to the detection scenarios that use them.
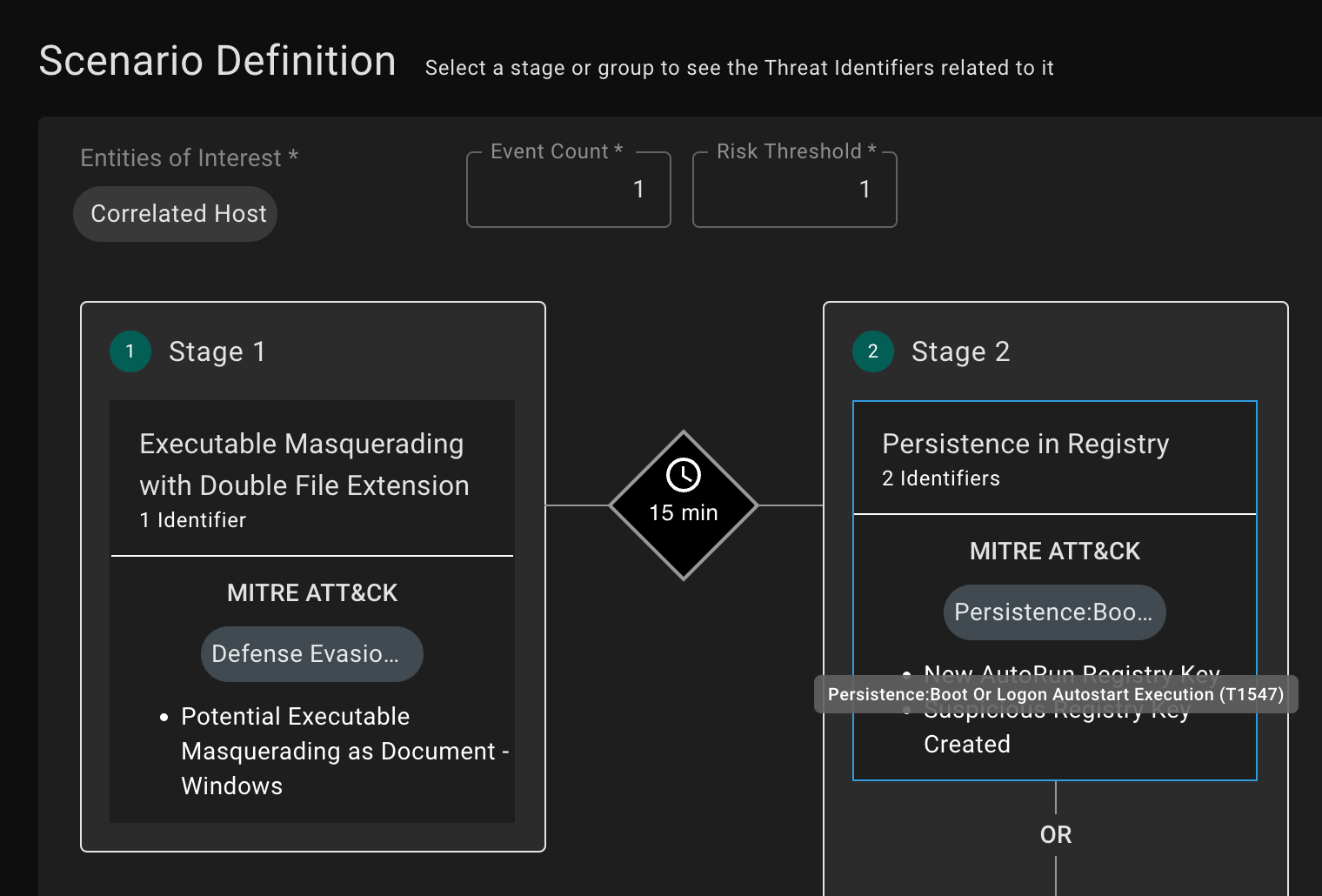
The example above defines a threat scenario where autostart manipulation follows an endpoint attack. There is no end to the ways in which an attacker can abuse autostart features in Windows. That’s why “coverage” for this persistence technique is counter-productive while using it to automatically pull in relevant new rules is helpful.
Making demonstrable progress toward covering your prioritized threat scenarios is a worthy outcome. MITRE ATT&CK can help with achieving that progress. And if you can’t cover the board and win the game, maybe that’s a sign that you’re doing real SOC work.
This makes me think of a librarian saying "we have 100% coverage of the dewey decimal system" about their library. It's more than a "common language", though — there's structure which might connect to other structures like attack trees. Would it make sense to e.g. systematically evaluate the MITRE matrix at each point in an org's attack tree to see which tactics and techniques apply in order to populate missing edges?