
Can Splunk Overcome Its Innovator's Dilemma?
The SIEM king's future depends on the answer.

In 2007, Beyoncé topped the charts with her hit song “Irreplaceable,” and BlackBerry commanded 40% of the U.S. smartphone market. Within five years, Queen Bey still reigned, but BlackBerry was virtually wiped out with less than 1% of the market. The Innovator’s Dilemma had made BlackBerry the opposite of irreplaceable. The future of the SIEM market hinges on whether Splunk is more like Beyoncé or BlackBerry.
A Winning Formula
IT, and later security teams, fell in love with Splunk’s fast and flexible search engine. In the early 2000s, the company pioneered an approach to centrally analyzing and troubleshooting vast amounts of event logs. Splunk made working with the icky structure of most machine data a more palatable experience.
At the heart of the platform’s success was its innovative indexing technology. Unlike traditional databases that required structured data input, Splunk was designed to handle a wide range of unstructured data. This flexibility allowed organizations to ingest logs, metrics, and other machine data without needing upfront schema definitions. What does this look like behind the scenes?
During ingestion, Splunk breaks down the data into individual events and stores them in an indexed format. This index is not a simple database table. It's a highly optimized structure that allows for lookups at a latency that supports real-time troubleshooting of IT issues like website outages and application crashes. Rapid searching is facilitated by storing raw data alongside metadata, such as timestamps, source types, and host information.
The appeal to IT teams organically extended to security operations, where the previous generation of Security Information and Event Management (SIEM) solutions like ArcSight were proving slow and cumbersome. Splunk was adopted across thousands of cybersecurity organizations, and revenues rose accordingly.

More Log Data, More Problems
Splunk became the dominant SIEM platform at a time when most enterprise infrastructure was in data centers. When its customers shifted to the cloud, Splunk struggled to adapt its architecture and pricing model. Customers became increasingly concerned when it became evident that cloud environments produce more log data—a lot more.
While I can’t cite a source for this specific figure, my experience has been that the shift to the cloud resulted in 3x more log data for a typical environment. This can be explained by the highly dynamic nature of Infrastructure-as-a-Service (IaaS). If you’re doing it right, cloud infra is constantly spinning up and down with new virtual machines, clusters, and entire networks, popping in and out of existence based on fluctuating user demands. Every change in the cloud is logged, hence terabytes of additional machine data for the security team to collect and analyze.
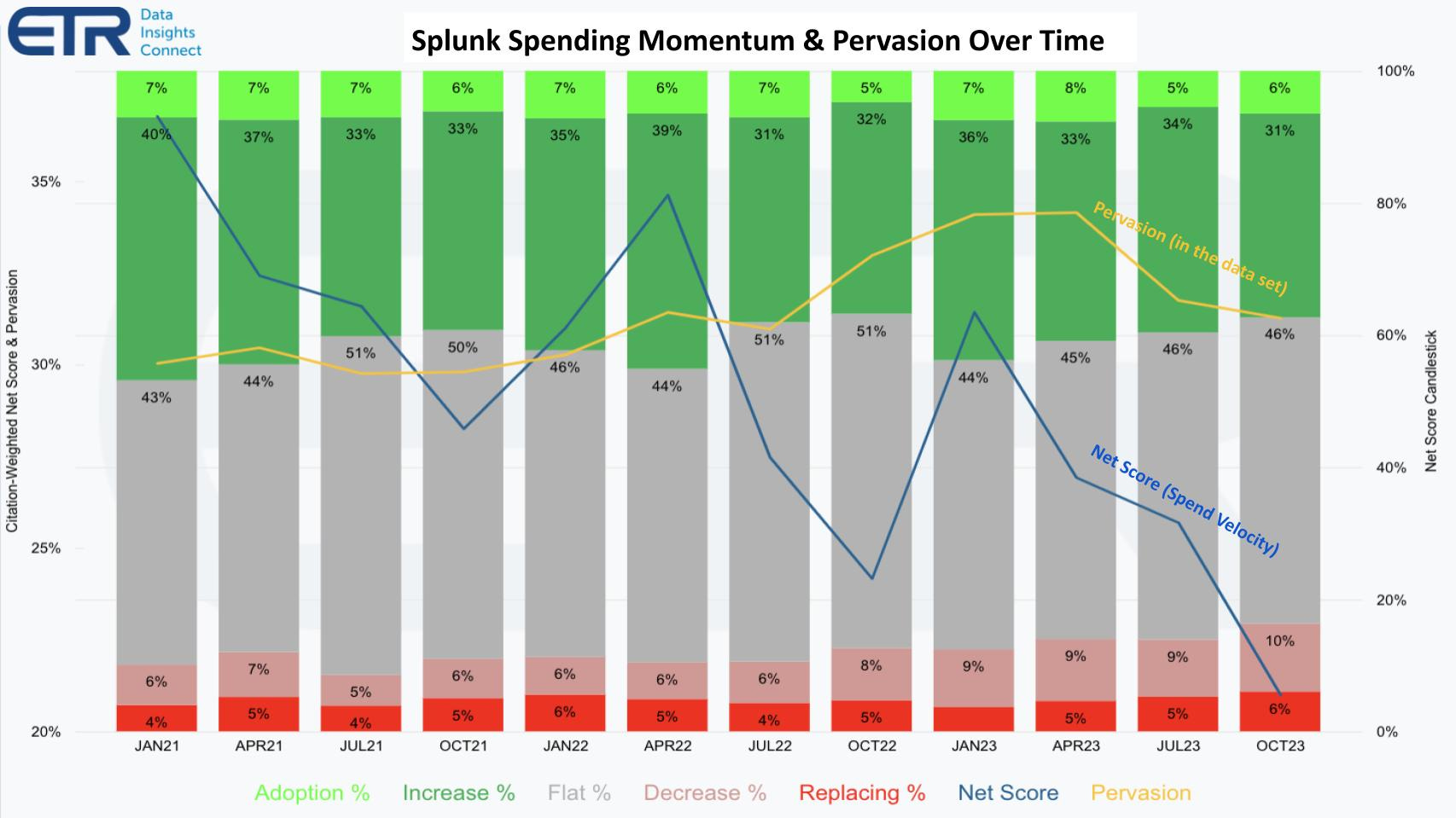
Splunk’s approach to indexing log data to support fast search became a source of constant cost concerns. This isn’t just anecdotal. In the customer spending data reported by SiliconAngle in 2023, a year-over-year downward trend can be seen in customer spending momentum. While 47% of customers reported plans to grow Splunk spending a few years prior, by the time the report was compiled, that number had dropped to 37%. Splunk was still prevalent in the polling data (yellow line below), but spending velocity was way down (blue line). The number of customers planning to decrease or eliminate Splunk spend had increased by over 50%.
This should not be interpreted as just a pricing problem. As explained in “Understanding Splunk’s New License Model: It’s Not the Pricing Model, It’s the Price Tag that Matters” by Cribl CEO Clint Sharp,
Offering additional models should not be confused with lowering prices. Changing models, for most customers, will offer at best marginal benefits… The use cases most likely to see lower query workloads are where Splunk is used as an online archive or primarily as an investigation tool without much scheduled workload. Additionally, if your users don’t particularly care about performance, you can likely ingest a lot more data but have a much poorer performing system with this license model.
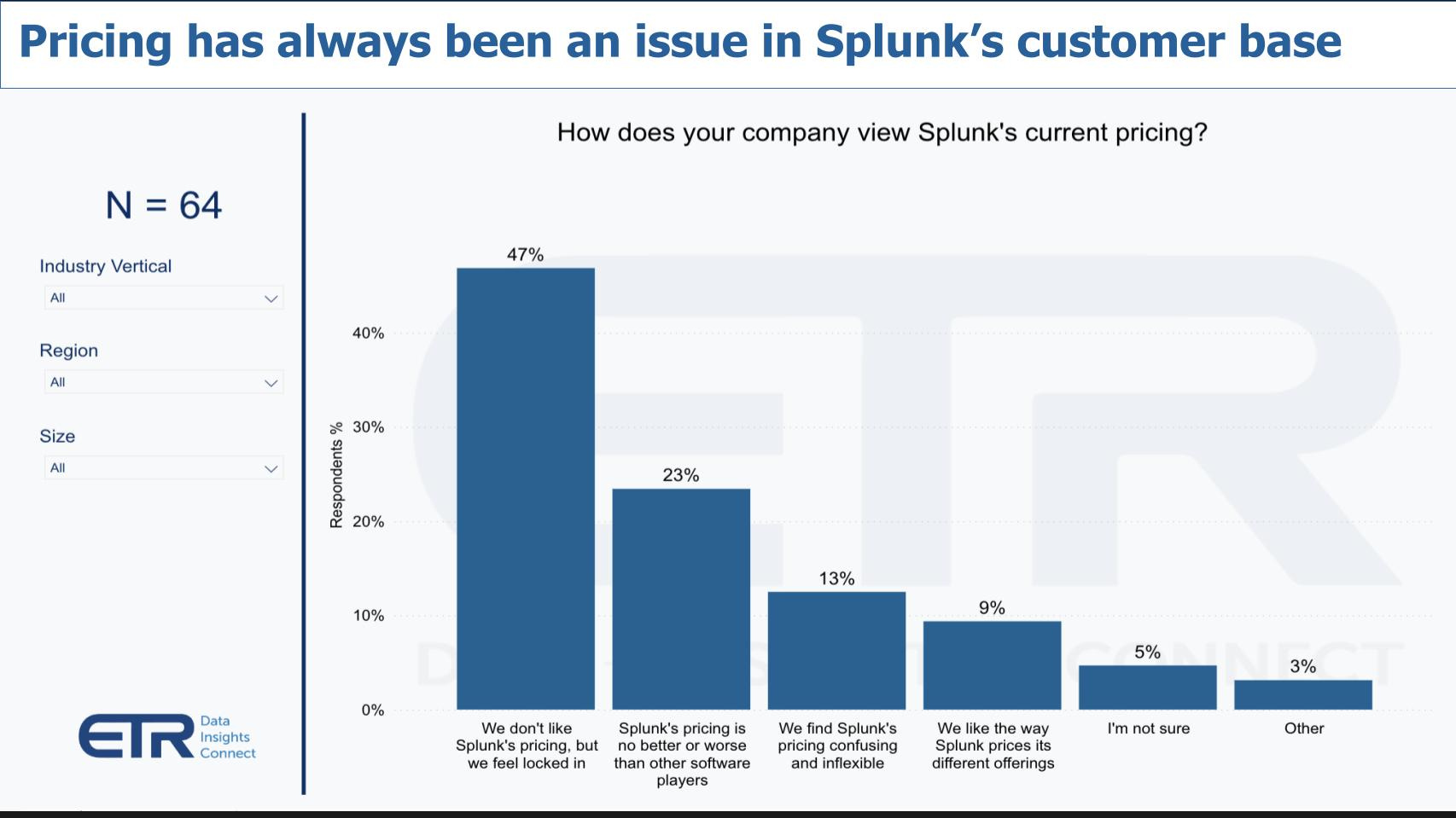
In other words, the historical vestiges of Splunk’s internal architecture are such that they struggle to deliver significant cost savings without making painful tradeoffs. This goes back to the indexing strategy that closely ties compute and storage. Without a fundamental redesign of how data is collected, stored, and searched, cost concerns have naturally increased with the inexorable shift to the cloud and the expansion of log volume. This is supported by a recent customer survey where the top response to the question of Splunk’s current pricing was: “We don’t like Splunk’s pricing, but we feel locked in.”
Dipping its Toe in the Data Lake
The challenge posed by the exploding volume of log data has not gone unnoticed. Dropping junk logs in transit is a fast way to slim down, but there’s a limit to how much data can be dropped before the security team flies blind. Using cheap cloud storage is another approach that offers a significant upside.
Consider that Splunk Cloud storage reportedly costs between $100-$150 per uncompressed TB a month (official figures are not available). Cloud-native options like Snowflake or S3 Parquet tables cost $23 per compressed TB a month. With log data compressed at a conservative 8x, the actual storage cost in the data lake is under $5/month per collected terabyte—a fraction of the Splunk cost.
Splunk didn't lose sight of the potential benefits of cloud-native data lakes for log data. Five years ago, the company launched Data Fabric Search (DFS) with support for external data lakes and Splunk indexes, aiming to provide a unified search experience across storage options.
Then, in 2021, Splunk launched a separate data lake product called Federated Search for Amazon S3. Done right, this could have enabled a rebalancing for customers looking to optimize between storage cost and search performance. With Federated Search, Splunk users could search against data in cheap cloud storage without paying for indexing upfront. Why has this feature not addressed the price concerns that are clearly still pervasive in the latest customer polls?
The first issue is performance. Splunk’s official documentation warns, “Customers attempting to use this feature for real-time searches will perceive slower performance and reduced search functionality when compared with indexed Splunk searches on ingested data.” How much slower depends on a number of factors but, unlike alternatives like Snowflake, scaling up when necessary is cumbersome and manual. An approach that can’t deliver a consistently adequate search experience will struggle to achieve widespread adoption.
The second issue is around predictability. Splunk added an additional cost component to Federated Search that meters by how much data is queried. The documentation states, “Customers need to acquire additional licensing to enable Federated Search for Amazon S3. This is based on "Data Scan Units", and is described as the total amount of data that all searches using Federated Search for Amazon S3 have scanned in the customer's Amazon S3 buckets. This licensing SKU is independent from Splunk Virtual Compute (SVC) and any Ingest based licenses that customers may have acquired.” It would be challenging to predict how much data a SOC will need to scan, and detection engineers may be discouraged from paying by the byte for scanning their log data throughout the day. An organization might figure out how much 100 saved search detection rules would cost. Now for every new rule they develop, what would be the cost in terms of Data Scan Units?
Finally, this approach might reduce storage costs but become more expensive overall. As Splunk’s documentation warns, “Customers attempting to use this feature for high frequency searches will likely incur higher costs than natively ingesting and searching in the Splunk platform.” The DSU model drives cost anxiety even higher as stated in the documentation, “that over the course of a year, the DSUs operate on a 'use it or lose it' model.” It’s no wonder that most Splunk customers have been unable to address their cost concerns with Federated Search.
Signs to Watch For
The shortcomings of Federated Search in Splunk are not necessarily here to stay. Security teams that have invested years into their Splunk deployment may be wondering if their puppy can learn new tricks. If this is you, what should you watch for in coming product and pricing announcements?
Telltale investment areas include the junk data cleanup that drove many big customers to adopt Cribl upstream from Splunk. Improving the usability and closing functionality gaps in Ingest Actions would indicate that Splunk is serious about addressing its spiraling ingest costs.
More importantly, watch for a Federated Search that does not actively discourage its users. The elimination of Data Scan Units as a tax on top of the already significant Virtual Compute cost would be a sign that Splunk is serious about enabling data lake adoption. If DSUs are not completely eliminated, they can still be changed. Successful cloud data platforms like Snowflake, BigQuery, and Databricks all offer time-based compute pricing due to its advantages over volume-based pricing. These include predictability (new detections don’t increase costs as long as they run in parallel) and affordability (speed improvements reduce run time, driving down costs). Charging by bytes-scanned only makes sense for limited, infrequent search use cases.
Cisco paid many billions for Splunk’s products and customer base. Will the new owners be able to overcome the innovator’s dilemma that threatens Splunk’s hold on the SIEM market? New competitors are leaning heavily on architectures that effectively expose the cost and scale efficiencies of the cloud. Splunk’s future depends on its ability to embrace flexible data storage options and customer data ownership.
Couldn't agree more. The idea that I have to pay more for searching data outside splunk is ridiculous and just confirmed that going with Cribl was the correct move.